





Why (Almost) Everything You Thought You Knew About Bit Depth Is Probably Wrong
A lot of competent audio engineers working in the field today have some real misconceptions and gaps in their knowledge around digital audio.
Not a month goes by that I don’t encounter an otherwise capable music professional who makes simple errors about all sorts of basic digital audio principles – The very kinds of fundamental concepts that today’s 22 year-olds couldn’t graduate college without understanding.
There are a few good reasons for this, and two big ones come to mind immediately:
The first is that you don’t really need to know a lot about science in order to make great-sounding records. It just doesn’t hurt. A lot of people have made good careers in audio by focusing on the aesthetic and interpersonal aspects of studio work, which are arguably the most important.
(Similarly, a race car driver doesn’t need to know everything about how his engine works. But it can help.)
The second is that digital audio is a complex and relatively new field – its roots lie in a theorem set to paper by Harry Nyquist 1928 and further developed by Claude Shannon in 1946 – and quite honestly, we’re still figuring out how to explain it to people properly.
In fact, I wouldn’t be surprised if a greater number of people had a decent understanding of Einstein’s theories of relativity, originally published in 1905 and 1916! You’d at least expect to encounter those in a high school science class.
If your education was anything like mine, you’ve probably taken college level courses, seminars, or done some comparable reading in which well-meaning professors or authors tried to describe digital audio with all manner of stair-step diagrams and jagged-looking line drawings.
It’s only recently that we’ve come to discover that such methods have led to almost as much confusion as understanding. In some respects, they are just plain wrong.
What You Probably Misunderstand About Bit Depth
I’ve tried to help correct some commonly mistaken notions about ultra-high sampling rates, decibels and loudness, the real fidelity of historical formats, and the sound quality of today’s compressed media files.
Meanwhile, Monty Montgomery of xiph.org does an even better job than I ever could of explaining how there are no stair-steps in digital audio, and why “inferior sound quality” is not actually among the problems facing the music industry today.
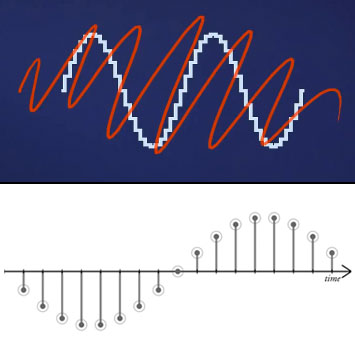
A bad way, and a better way to visualize digital audio. Images courtesy Monty Montgomery’s Digital Show and Tell video. (Xiph.org)
After these, some of the most common misconceptions I encounter center around “bit depth.”
Chances are that if you’re reading SonicScoop, you understand that the bit depth of an audio file is what determines its “dynamic range” – the distance between the quietest sound and the loudest sound we can reproduce.
But things start to go a little haywire when people start thinking about bit depth in terms of the “resolution” of an audio file. In the context of digital audio, that word is technically correct. It’s only what people think the word “resolution” means that’s the problem. For the purpose of talking about audio casually among peers, we might be even better off abandoning it completely.
When people imagine the “resolution” of an audio file, they tend to immediately think of the “resolution” of their computer screen. Turn down the resolution of your screen, and the image gets fuzzier. Things get blockier, hazier, and they start to lose their clarity and detail pretty quickly.
Perfect analogy, right? Well, unfortunately, it’s almost exactly wrong.
All other things being equal, when your turn down the bit depth of a file, all you’ll get is an increasing amount of low-level noise, kind of like tape hiss. (Except that with any reasonable digital audio file, that virtual “tape hiss” will be far lower than it ever was on tape.)
That’s it. The whole enchilada. Keep everything else the same but turn down the bit depth? You’ll get a slightly higher noise floor. Nothing more. And, in all but extreme cases, that noise floor is still going to be – objectively speaking – “better” than analog.
On Bits, Bytes and Gameboys
This sounds counter-intuitive to some people. A common question at this point is: “But what about all that terrible low-resolution 8-bit sound on video games back in the day? That sounded like a lot more than just tape hiss.”
That’s a fair question to ask. Just like with troubleshooting a signal path, the key to untangling the answer is to isolate our variables.
Do you know what else was going on with 8-bit audio back in the day? Here’s a partial list: Lack of dither, aliasing, ultra-low sampling rates, harmonic distortion from poor analog circuits, low-quality dither, low-quality DA converters and filters, early digital synthesis, poor quality computer speakers… We could go on like this. I’ll spare you.
Nostalgia, being one of humanity’s most easily renewable resources, has made it so that plenty of folks around my age even remember some of these old formats fondly. Today there are electronic musicians who make whole remix albums with Nintendos and Gameboys, which offer only 4 bits of audio as well as a myriad of other, far more significant issues.
(If you like weird music and haven’t checked out 8-Bit Operators’ The Music of Kraftwerk, you owe it to yourself. They’ve also made tributes to Devo and The Beatles.)
But despite all that comes to mind when we think of the term “8 Bits,” the reality is that if you took all of today’s advances in digital technology and simply turned down the bit depth to 8, all you’d get is a waaaaaaay better version of tape cassette.
There’d be no frequency problems, no extra distortion, none of the “wow” and “flutter” of tape, nor the aliasing and other weird artifacts of early digital. You’d just have a higher-than-ideal noise floor. But with at least 48 dB of dynamic range, even the noise floor of modern 8-bit audio would still be better than cassette. (And early 78 RPM records, too.)
Don’t take my word for it. Try it yourself! Many young engineers discover this by accident when they first play around with bit-crushers as a creative tool, hoping to emulate old video game-style effects. They’ll often become confused and even disappointed to find that simply lowering the bit count doesn’t accomplish 1/50th of what they were hoping for. It takes a lot more than a tiny touch of low-level white noise to get a “bad” sounding signal.
The Noise Floor, and How It Effects Dynamic Range
This is where the idea of “dynamic range” kicks in.
In years past, any sound quieter than a certain threshold would disappear below the relatively high noise floor of tape or vinyl.
Today, the same is true of digital, except that the noise floor is far lower than ever before. It’s so low, in fact, that even at 16 bits, human beings just can’t hear it.
An 8-bit audio file gives us a theoretical noise floor 48dB below the loudest signal it can reproduce. But in practice, dithering the audio can give us much more dynamic range than that. 16-bit audio, which is found on CDs, provides a theoretical dynamic range of 96dB. But in practice it too can be even better.
Let’s compare that to analog audio:
Early 78 RPM records offered us about 30-40 dB of dynamic range, for an effective bit depth of about 5 -6 bits. This is still pretty useable, and it didn’t stop people from buying 78s back in the day. It can even be charming. It’s just nowhere near ideal.
Cassette tapes started at around 6 bits worth of “resolution”, with their 40 dB of dynamic range. Many (if not most) mass-produced cassettes were this lousy. Yet still, plenty of people bought them.
If you were really careful, and you made your tapes yourself on nice stock and in small batches, you could maybe get as much as 70dB of dynamic range. This is about equivalent to what you might expect out of decent vinyl.
Yes, it’s true, it’s true. Our beloved vinyl, with its average dynamic range of around 60-70dB, essentially offers about 11 bits worth of “resolution.” On a good day.
Professional-grade magnetic tape was the king of them all. When the first tape players arrived in the U.S. after being captured in Nazi Germany at the end of World War II, jaws dropped in the American music community. Where was the noise? (And you could actually edit and maybe even overdub? Wow.)
By the end of the tape era, you could get anywhere from 60dB all the way up to 110dB of dynamic range out of a high-quality reel – provided you were willing to push your tape to about 3% distortion. Those were the tradeoffs. (And even today, some people still like the sound of that distortion in the right context. I know I do.)
Digital can give us even more signal-to-noise and dynamic range, but at a certain point, it’s our analog circuits that just can’t keep up. In theory, 16-bit digital gives us 96 dB of dynamic range. But in practice, the dynamic range of a 16-bit audio file can reach well over 100 dB – Even as high as 120 dB or more.
This is more than enough range to differentiate between a fly on the wall halfway across your home and a jackhammer right in front of your face. It is a higher “resolution” than any other consumer format that came before it, ever. And, unless human physiology changes over some stretch of evolution, it will be enough “resolution” for any media playback, forever.
Audio capture and processing however, are a different story. Both require more bits for ideal performance. But there’s a limit as to how many bits we need. At a certain point, enough is enough. Luckily, we’ve already reached that point. And we’ve been there for some time. All we need to do now is realize it.
Why More Bits?
Here’s one good reason to switch to 24 bits for recording: You can be lazy about setting levels.
24 bits gives us a noise floor that’s at least 144 dB below our peak signal. This is more than the difference between leaves rustling in the distance and a jet airplane taking off from inside your home.
This is helpful for tracking purposes, because you have all that extra room to screw up or get sloppy about your gain staging. But for audio playback? Even super-high-end audiophile playback? It’s completely unnecessary.
Compare 24-bit’s 144 dB of dynamic range to the average dynamic range of commercially available music:
Even very dynamic popular music rarely exceeds 4 bits (24dB) or so worth of dynamic range once it’s mixed and mastered. (And these days, the averages are probably even lower than that, much to the chagrin of some and the joy of others.) Even wildly dynamic classical music rarely gets much over 60 dB of dynamic range.
But it doesn’t stop there: 24-bit consumer playback is such overkill, that if you were able to set your speakers or headphones loud enough so that you could hear the quietest sound possible above the noise floor of the room you were in (let’s say, 30db-50dB) then the 144 dB peak above that level would be enough to send you into a coma, perhaps even killing you instantly.
The fact is, that when listening to recorded music at anything near reasonable levels, no one is able to differentiate 16-bit from 24-bit. It just doesn’t happen. Our ears, brains and bodies just can’t process the difference. To just barely hear the noise floor of dithered 16 bit audio in the real world, you’d have to find a near-silent passage of audio and jack your playback level up so high that if you actually played any music, you’d shear through speakers and shatter ear drums.
(If you did that same test in an anechoic chamber, you might be able to get away with near-immediate hearing loss instead. Hooray anechoic chambers.)
But for some tasks, even 24-bits isn’t enough. If you’re talking about audio processing, you might go higher still.
32 Bits and Beyond
Almost all native DAWs use what’s called “32-bit Floating Point” for audio processing. Some of them might even use 64 bits in certain places. But this has absolutely no effect on either the raw sound “quality” of the audio, or the dynamic range that you’re able to play back in the end.
What these super-high bit depths do, is allow for additional processing without the risk of clipping plugins and busses, and without adding super-low levels of noise that no one will ever hear. This extra wiggle room lets you do insane amounts of processing and some truly ridiculous things with your levels and gain-staging without really thinking twice about it. (If that happens to be your kind of thing.)
To get the benefit of 32-bit processing, you don’t need to do anything. Chances are that your DAW already does it, and that almost all of your plugins do too. (The same goes for “oversampling,” a similar technique in which an insanely high sample rate is used at the processing stage).
Some DAWs also allow the option of creating 32-bit float audio files. Once again, these give your files no added sound quality or dynamic range. All this does is take your 24-bit audio and rewrite it in a 32-bit language.
In theory, the benefit is that plugins and other processors don’t have to convert your audio back and forth between 24-bit and 32-bit, thereby eliminating any extremely low-level noise from extra dither or quantization errors that no one will ever hear.
To date, it’s not clear whether using 32-bit float audio files are of any real practical benefit when it comes to noise or processing power. The big tradeoff is that they do make all of your projects at least 50% larger. But if you have the space and bandwidth to spare, it probably can’t hurt things any.
Even if there were a slight noise advantage at the microscopic level, it would likely be smaller than the noise contribution of even one piece of super-quiet analog gear.
Still, if you have the disk space and do truly crazy amounts of processing, why not go for it? Maybe you can do some tests of your own. On the other hand, if you mix on an analog desk you stand to gain no advantage from these types of files. Not even a theoretical one.
A Word On 48-bit
Years ago, Pro Tools, probably the most popular professional-level DAW in America, used a format called “48-Bit Fixed Point” for its TDM line.
Like 32-bit floating, this was a processing format, and it had pretty much nothing to do with audio capture, playback, or effective dynamic range.
The big difference was in how it handled digital “overs”, or clipping. 32-bit float is a little bit more forgiving when it comes to internal clipping and level-setting. The tradeoff is that it has a potentially higher, and less predictable noise floor.
The noise floor of 48-bit fixed processing was likely to be even lower and more consistent than 32-bit float, but the price was that you’d have to be slightly more rigorous about setting your levels in order to avoid internal clipping of plugins and busses.
In the end, the differences between the two noise floors is basically inaudible to human beings at all practical levels, so for simplicity’s sake, 32-bit float won the day.
Although the differences are negligible, arguing about which one was better took up countless hours for audio forum nerds who probably could have made better use of that time making records or talking to girls.
All Signal, No Noise
To give a proper explanation of the mechanics of just how the relationship between bit depth and noise floor works (and why the term “resolution” is both technically correct and so endlessly misleading for so many people) would be beyond the scope of this article. It requires equations, charts, and quite possibly, more intelligence than I can muster.
The short explanation is that when we sample a continuous real-world waveform with a non-infinite number of digital bits, we have to fudge that waveform slightly in one direction or another to have it land at the nearest possible bit-value. This waveform shifting is called a “quantization error,” and it happens every time we capture a signal. It may sound counter-intuitive, but this doesn’t actually distort the waveform. The difference is merely rendered as noise.
From there, we can “dither” the noise, reshaping it in a way that is even less noticeable. That gives us even more dynamic range. At 16 bits and above, this practically unnecessary. The noise floor is so low that you’d have to go far out of your way to try and hear it. Still, it’s wise to dither when working at 16 bits, just to be safe. There are no real major tradeoffs, and only a potential benefit to be had. And so, applying dither to a commercial 16-bit release remains the accepted wisdom.
Now You Know
If you’re anything like me, you didn’t know all of this stuff, even well into your professional career in audio. And that’s okay.
This is a relatively new and somewhat complex field, and there are a lot of people who can profit on misinforming you about basic digital audio concepts.
What I can tell you is that the 22-year olds coming out of my college courses in audio do know this stuff. And if you don’t, you’re at a disadvantage. So spread the word.
Thankfully, lifelong learning is half the point of getting involved in a field as stimulating, competitive and ever-evolving as audio or music.
Keep on keeping up, and just as importantly, keep on making great records on whatever tools work for you – Science be damned.
Please note: When you buy products through links on this page, we may earn an affiliate commission.
John Lardinois
January 9, 2015 at 10:44 am (10 years ago)It is – that’s why the sample rate is 44.1 and not 40. I simply was using numbers that were consistent with 20kHz human hearing range so as to not confuse those who are not familiar with how nyquist filters and sample rates work.
I figured there are people who are reading this who have never heard of a nyquist filter, but know that human hearing goes up to 20k (common knowledge).
I meant it as a way to simplify the explanation for the readers who are new to digital audio theory. So, yes, you are correct. I merely meant it as a simpler, cleaner response for the new guys.
T_Thrust
January 9, 2015 at 7:02 pm (10 years ago)ahh, got ya.
Kon
April 12, 2015 at 5:05 pm (10 years ago)Thanks for sharing this knowledge… the Internet needs more guys like you, seriously.
Eric D. Ryser
May 29, 2015 at 10:24 am (10 years ago)Yep. I have tin ears, okay? and even I can hear very non-subtle quantization errors when I use my 16 bit recorder, especially when the sound is “Morendo”. Admittedly, this is probably due more to the quality of the digital signal converters than anything, but that doesn’t take away from the fact that, as you point out, given more resolution that conversion will have less error. This article is wrong in it’s basic premise, that bit depth is not “about” resolution…because it’s exactly about resolution.
preferred user
August 5, 2015 at 7:48 pm (10 years ago)16/44.1 lower Nyqist rate is close @ 22.5kHz i.e. ½ of 44.1kHz
Bob Fridz
October 1, 2015 at 11:17 am (9 years ago)Nice article but aren’t a lot of people failing to mention or realize that in a studio people often stack up multiple tracks to make an arrangement. This can be 100+ tracks nowadays in pop music, but it happens in all genres.
One might not be able to hear the difference between a 16 bit finished track or a 24 bit finished track, but I am 1000% sure everyone can hear the difference between a mix built up out of 100+ 16bit tracks or a 100+ 24 bit tracks. Same goes for 44.1 up to 192khz.
Record a drumkit with 15 mics (close, mid and room) and have a drummer play the same beat and fills. Record a section at 16bit 44.1khz and record a similar section at 24bit 192khz.
I will put money on this: everyone will hear the difference! And no it’s not magic. 24/192 isn’t amazing, it’s just the most accurate way of capturing sound.
Downgrading a 24/192 mix to 16/44.1 afterward will still sound better than doing the whole process at 16/44.1 from the start.
JSchmoe
April 27, 2016 at 5:58 pm (9 years ago)“Anything quieter than the noise floor just can’t be heard”
This is completely inaccurate. Think a little more.
Justin C.
April 28, 2016 at 9:28 am (9 years ago)It is indeed my job to think about these things, Mr. Schmoe. If you’d like to make a reasoned counterargument, or provide some evidence to support your assertion, then great! If not, then this doesn’t add much to the conversation.
Until then, yes, the original statement is correct: Any signal that is lower in level than the noise floor will, by definition, be masked by the noise floor and be indistinguishable from the random, full-spectrum noise.
One caveat that may be worth noting is that the noise floor can potentially be at a slightly different level at different frequencies, but the essential concept, and the original statement, still holds, even with this caveat.
Mark K.
June 14, 2016 at 2:56 pm (9 years ago)“Any signal that is lower in level than the noise floor will, by definition, be masked by the noise floor and be indistinguishable from the random, full-spectrum noise.”
That’s utter nonsense. Humans can pick up patterns WAY below the noise floor. E.g:
http://ethanwiner.com/audibility.html
Physicsonboard
July 30, 2016 at 4:41 pm (9 years ago)This is partially true, but it is not what the studies suggest. The double blind studies showed that a higher proportion of “super listeners” preferred the lower resolution files, no one knows why. OTOH, the idea that one should rely on science when making an audio recording is as ridiculous as making a painting using “color by number.”
George Piazza
March 10, 2017 at 2:00 pm (8 years ago)I have one question for you John: Do you convert your files to 96 kHz before mixing them, or do you simply set your DAW to output a 96kHz file?
If you do the latter, ask yourself – Where is the DAW converting the data into 96 kHz? Before the first mixing calculation? Really?
Or, as is much more likely, the whole mix is happening at the original sample rate, then the DAW is up-converting the final output to 96 kHz? Therefore, none of the EQs & other processors are ever seeing 96 kHz (except for the ones that have internal up-sampling as part of their processing). All you are doing is up-converting a stereo file after the mixing.
I have seen a number of people who say they do what you do, but if you check your CPU usage, does it double when you mix out at double the original file sample rates? Or at least go up substantially, taking into account the number of plugins that already up-sample – down-sample the data stream? And if the session (and converter) are still set to 48 kHz, is it reasonable to assume that you are getting 96 kHz processing throughout? Even if you set the DAW to 96 kHz playback, you are now playing back 48 kHz files at twice their speed! Without changing the actual processing sample rate of the calculations. (and the ‘mix’ file would probably sound rather odd.. you know, like the chipmunks on meth!).
I have yet to see a DAW manufacturer that unequivocally specifies the actual location of the up-sampling when the output medium is set at a higher sample rate, but the logic dictates that 48 kHz files playing back at 48 kHz will be processed at 48 kHz, then up-sampled to 96 kHz upon output.
Therefore, the only way to assure all processing takes place at 96 kHz is to batch up-sample every file, set the DAW at the new sampling rate (96 kHz) and then mix. Hope you consolidate all your files first!
John Morris
April 16, 2017 at 12:54 am (8 years ago)I have been trying to educate people on this for years. If you think this is bad try explaining to amateur engineers that 0dbfs (digital full scale) doesn’t equal 0vu. 0vu or rather 0dbu for 24 bit is -18dbfs RMS (average level not peak) I tell them their converters will sound better if they run them at the level they were designed to operate at. Average at -18dbfs (between -22 and – 12dbfs) and don’t peak beyond -6dbfs but I get this, “The closer you get to 0dbfs the more bits you use, so the better it sounds…” amateur engineers recording too hot has become a big problem. Even some professionals with million dollar studios, who should know better are doing this “max it out to zero” foolishness.
Nathan Nanz
July 29, 2017 at 11:42 am (8 years ago)Justin, it’s well-established that program -can- be heard under a “random noise floor.” Sometimes as much as 20-25dB below a noise floor, depending on the nature of the program (e.g., periodic tones in the most ear-sensitive mid-freq band). I actually did a similar experiment recently with -40dBu “broadband, uncorrelated noise” and a -60dBu 2kHz sine wave. Very easy to detect the sine wave 20dB under the noise floor.
Also wondering about your assertion that “in practice, the dynamic range of a 16-bit audio file can reach … as high as 120 dB or more.” Can you elaborate on this? Is there an objective test or study that you can cite? Tks.
Nathan Nanz
July 29, 2017 at 1:47 pm (8 years ago)When you look at the raw output of DACs with low-level program, the waveforms are jaggy and distorted, a product of low-level non-linearity. Not “stair-stepped” but simply errors leading to huge THD. Stereophile Magazine often publishes a -90dBFS sine wave (which is quite audible) at the output of a DAC. It’s not pretty. I’ve uploaded an example plot of a $23,000 DAC from Meridian, called the Ultra DAC, released in 2017.
https://uploads.disquscdn.com/images/55ffeeda24ac813e9745f80bafda1e8295581c0c47107ff9fb1aebed8520fb59.jpg
https://www.stereophile.com/content/meridian-audio-ultra-dac-da-processor-measurements
This is what happens in D-A processing as the waveform approaches the “error floor” of the DAC. In lesser quality DACs, the low-level distortion is far worse, apparent even at -70dBFS. Compare this effect with analog (tape, etc.). As the program approaches the analog noise floor, it remains undistorted — no jaggies. The waveform remains relatively pure, and it falls into the noise.
There’s a theory that people often prefer the “sound” of analog (tape, vinyl, etc.) because it manages low-level signals more linearly than digital (see above). It’s an interesting theory. A holy grail of DAC design is to
eliminate all low-level “jaggy error” distortion, so that even at
-100dBFS or -110dBFS, the program signal remains pure and “jaggy free.” When that happens, digital processing will become far closer to analog reality.
Nathan Nanz
August 1, 2017 at 9:23 pm (8 years ago)When you look at the raw output of DACs with low-level program, the
waveforms are jaggy and distorted, a product of low-level non-linearity.
Not “stair-stepped” but simply errors leading to huge THD. Stereophile
Magazine often publishes a -90dBFS sine wave (which is quite audible) at
the output of a DAC. It’s not pretty. In lesser quality DACs, the low-level distortion is far worse,
apparent even at -70dBFS. Compare this effect with analog (tape, etc.).
As the program approaches the analog noise floor, it remains undistorted
— no jaggies. The waveform remains relatively pure as it falls into
the noise.
There’s a theory that people often prefer the “sound”
of analog (tape, vinyl, etc.) because it manages low-level signals more
linearly than digital (see above). It’s an interesting theory. A holy
grail of DAC design is to eliminate all low-level “jaggy error”
distortion, so that even at -100dBFS or -110dBFS, the program signal
remains pure and “jaggy free.” When that happens, digital processing
will become far closer to analog reality. Sure, dither can help, but not with a DAC’s inherent non-linearity.
codehead
August 14, 2017 at 6:22 pm (8 years ago)Good comment, so hate to be picky with details, but 32-bit floats actually encode 25 bits of precision along with the 8-bit exponent. (It does this by keeping the mantissa “normalized”, at 1.xxxxxx raised to the exponent, and omitting the leading “1”. Specifically, the mantissa uses 23 bits, a sign bit, and the implied bit, for 25-bits.)
Dreadrik
August 31, 2017 at 10:35 am (7 years ago)I’m not sure about other DAW’s, but when setting the output sample frequency in e.g. Propellerhead Reason, you set it for the whole project, including all devices and plugins. All samples and recordings used that has a different sampling frequency will be sample rate converted in the device they are played, before continuing to the next processing step.
CPU usage will increase, but not be doubled, since sample buffer manipulation is not the only thing happening in a DAW.
George Piazza
September 1, 2017 at 4:59 pm (7 years ago)Does it clearly say that in the Reason manual (‘all devices and plugins’)? ? Specifically, does it say SRC is done before all processing, or something to that effect?
If the manual does not specify, how can you be sure?
The operative word in your description of the setting is ‘Output Sample Frequency’. If that is the only description of what the setting is / does, it seems to imply that the output (post processing) is up-sampled. Again, if that is the case, the DAW is still processing the mix at the original sample rate and then up-sampling the output, which is very different from up-sampling each source audio (as it is read from storage or generated by Virtual Instrument) and then processing the up-sampled audio.
In either case, you are at the mercy of the built in SRC (up-sampling & down-sampling). Some DAWs have decent to very good sample rate converters; other are not so good. Here is a site that shows various measurements of different sample rate converters (DAWs, Standalone Programs, Hardware): http://src.infinitewave.ca/
Reason 7 & 8 look really good, but 6.5 and earlier are terrible.
George Piazza
September 1, 2017 at 5:10 pm (7 years ago)Ha, John.. try to explain jitter in layman’s terms! That’s always a fun road to travel (i.e. a verbal morass)…
Again though, how can you be sure your DAW is up-converting the source audio BEFORE processing? I have not yet seen a DAW manual or other info that explicitly says that creating a mix at a different sample rate will convert the audio before processing. Actually, I have reason to suspect that most, if not all, DAWs mix at the source audio sample rate (excluding plugins that up-sample during processing), the convert the output to the destination sample rate. Then there is the quality of the SRC built into various DAWs. Here is a site that has measurements of different SRCs (in DAWs, standalone programs and hardware): http://src.infinitewave.ca/
George Piazza
September 1, 2017 at 5:38 pm (7 years ago)25 bits, which give it a dynamic range of 151 dB; but the 8 bit exponent allows for very large and very small numbers, thus the near impossibility of overloading within a floating point stream. The dynamic range limitation is built into the math floating point can handle very small numbers and very large numbers, but no number can extend beyond the precision of the mantissa (i.e. very small numbers are ‘drowned out’ by large numbers. The biggest advantage to Floating Point is the extra calculation precision during processing.. Dynamics and Reverbs in particular are better handled in F.P. but even simple gain changes will benefit.
Dreadrik
September 1, 2017 at 6:05 pm (7 years ago)I know for a fact, since I used to be a developer at Propellerheads. 🙂 Audio is resampled at the source. All processing is done at the set output sample rate. (I don’t remember right now if the setting says “output sample rate” or simply “sample rate”).