





Research & Development: iZotope VocalSynth Vocal Processing Plugin
This plugin started with a playlist.
When the Boston-based developer iZotope committed to creating an all-in-one vocal processing plugin, the first step had nothing to do with writing code. Instead, the design team compiled a big playlist of songs present and past led by classic or innovative vocals, then began organizing their next brainchild around what they heard.
The result is VocalSynth, which makes complex vocal processing possible by tweaking just a few paramaters. Its built around four core vocal processing engines: vocoder (the voice as foundation for robotic vocals), polyvoice (organic harmonies), compuvox (glitchy digital speech) and Talbox (singing synthesized sounds). Each modules can be easily blended – the perfect platform for concocting highly original effects in no time.
iZotope’s product manager for the music products line, Matt Hines, is about to walk us through how a creative new plugin like this gets made – who is a toolkit like this for, and what was the workflow that made it possible? Plug in to some essential audio information.
You said that iZotope is “never not planning for the future.” How does that inform what new products you choose to develop?
We keep a constant eye not just on the concrete feature requests for any given product, but also on outcomes people may be looking for.
People may not always articulate exactly what a feature should but, but the outcomes are more interesting… is there a sound they’re seeking, or a technique they’re looking to be able to make use of, or a trend that’s inspiring? Are there things people wish they could do, but no audio processor is yet capable of?
This helps us look beyond what’s out right now, and think about what people may want tomorrow, and of course then use this runway to research and develop prototypes, which then informs a product we ultimately develop.
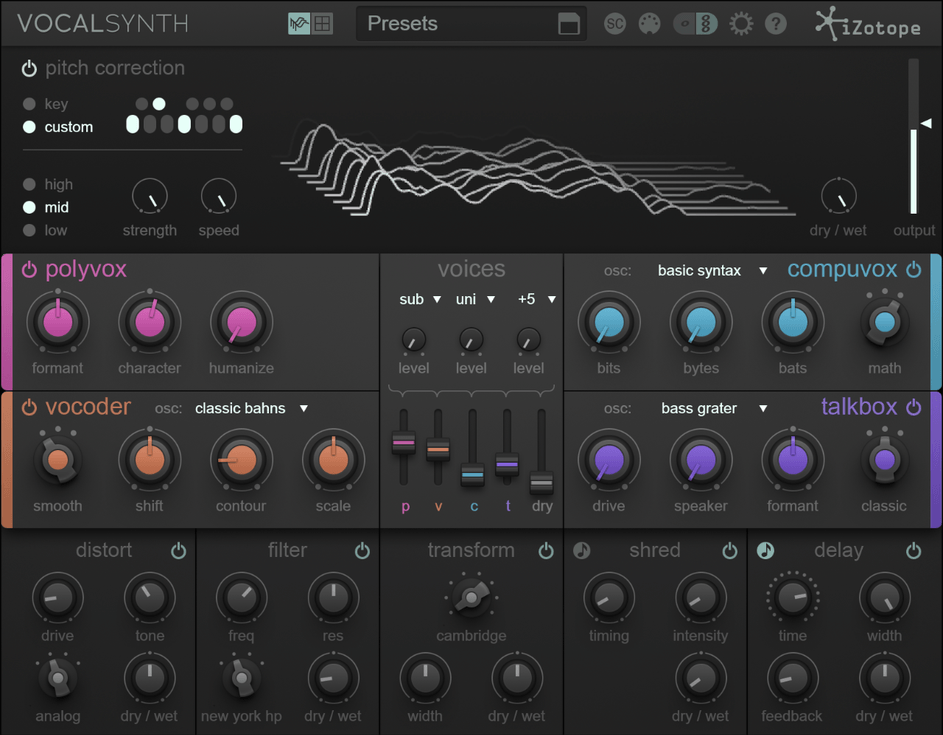
All four cores are accessible at once, leading to one output.
From there, what made VocalSynth a priority for iZotope to develop? What did you see happening in the audio marketplace that told you this type of tool was needed?
Vocal processing has always been popular, never more so than at present.
The vocal is everything… it’s used as the lead synth, the percussive elements, the chordal elements, it’s manipulated in so many ways by so many fun processors.
We actually had a large playlist of songs we felt were defined by signature vocal processing… and after asking ourselves “What tools would we need to sound like these songs?” we came up with VocalSynth. It’s very versatile, and can go after a lot of popular sounds past and present, but we’re really hoping that people will use it to discover something new.
How do you see the needs of artists and audio professionals changing, from an ergonomic, creative and sonic standpoint?
The boundaries of musical genres are blurring more and more as genres converge, and pop, EDM, country, rock, metal, hip hop and rap learn from and pay homage to one another.
From a creative and a sonic standpoint, it’s no longer unusual to hear a country song using a beat repeat effect, or a rock band using a vocoder, or a pop track hitting just as hard in the club as an EDM track. It’s not that the sounds are homogenizing, but rather that people are figuring out new and exciting ways to take genres based on this new types of processing.
Ergonomically, the tools are ever more democratized, but I see a gap in the sounds people want to achieve, and the ease with which many tools empower them to achieve those sounds, which is where VocalSynth comes in.
We hope the unique combination of so many different processors in one, as well as a few things that haven’t yet been done in software, will let people not just sound like their heroes, but become the next hero with their own sound.
Heroes are needed right now! So how did this evolution lead to the initial vision for VocalSynth – what did you see as the big technical and creative opportunities that would result from an “ultimate vocal effects laboratory?
We didn’t want to make a tool that was pigeonholed into any one genre, so seeing this evolution happen over time, we made sure to continually reference our original idea and make sure we could still sound like x, y or z as well as deciding something new. That’s the creative opportunity.
Oh, and VocalSynth is incredible for super-hero/villain style voice futz effects too.
On the other hand, what did you discover would be the most significant challenges you would face in realizing that vision?
Probably the most significant technical challenge, a challenge solved not by me but by the incredible teamwork that went into this product, was the Talkbox module.
Conventional talkboxes are of course a compression driver, which transduces the input into the metal housing, and up the PVC piping. This alone has a distinctive sound, let alone what happens next, as the audio is shaped and filtered by the user’s mouth and lips, before being transduced again by the mic.
We had to build a tool capable of analyzing the audio input signal and extracting with the utmost accuracy an envelope of what that particular vocalist’s mouth and lips were doing to the buzz from the vocal cords. It’s different for every user, and it’s also quite different from other types of audio processing, which is why we’ve seen plenty of software vocoders, but really no accurate talkbox emulations, even though vocoders and talkboxes do share some similarities.
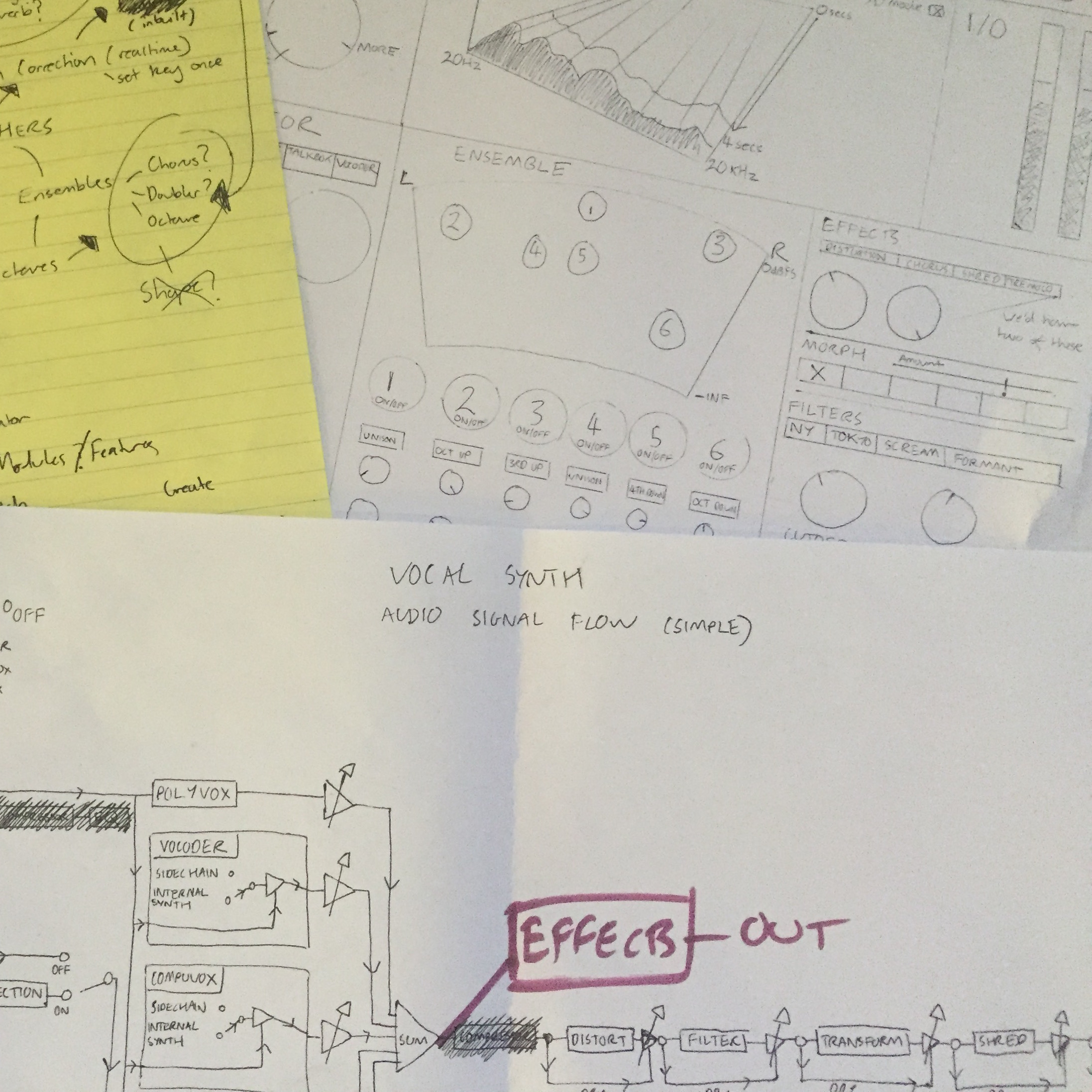
Early developmental sketches that preceded the final GUI.
What are the major stages of the design process at iZotope – what had to happen in order for VocalSynth to move from concept to prototype to finished product?
I mentioned a playlist above. Understanding the tools we would need to go after those sounds is what lead to some hand sketches, on paper and on whiteboard, of what this crazy thing could look like.
We then built it up in Max/MSP, purely to prototype dimensions, potential controls and layouts, with very rudimentary audio processing in the background. This was a lot cheaper than code, and helped answer many questions. We threw out a lot more than we kept in, but also, keep in mind that if you’re moving one knob on the vocoder, it may well be controlling multiple things under the hood. This thing is doing hundreds of processes at once.
Once we began to build VocalSynth proper, we already knew what we had was fun, so seeing it come together was very rewarding, and we had some user interface iteration, and some experimental projects… such as the wave-meter display, which lives and breaths with the way the vocal rises and falls.
Working outside of the box, iZotope has its own recording studio. How was this helpful for your team as you developed VocalSynth?
We had our builds installed regularly in the studio, and used this as an opportunity to invite folks to come in, sit down, perform and play with VocalSynth as it evolved. This really helped dial in user interface/experience and also DSP feedback.
Who will be the early adopters of VocalSynth — and what type user do you think will need some convincing?
Anyone who’s producing music, honestly, should and may well be an early adopter. That’s a grand statement, but it’s incredibly fun and exciting to use.
I think non-vocalists may take some convincing, but it’s OK, I rarely have anything but 100% wet signal when I’m using VocalSynth… no one wants to hear any of my dry voice. And in fact, sometimes you don’t sing so much as articulate to get that crisp result from a vocoder or a talkbox.
Now that it’s out in the market, how do you decide what feedback to incorporate ASAP into the next version, versus putting on the list to do later?
We’ll often ask the beta to rank their priorities, talk with users more to understand why they feel more or less strongly about one thing over another, and that’s step one.
Step two is always to understand the feasibility of any change to the code, which varies depending on the timeframe, and what it involves… it could be fixing a bug or a stability issue, or a major functional change to the way something works or sounds.
Lastly, what did you learn not just about audio software creation, but the human voice itself as an instrument, from this project?
We certainly gained a new understanding not just of the well documented science behind human speech, but how to extract and re-create that in the software domain.
We also explored the boundaries of Linear Predictive Codec technologies, which is nothing new, but we felt we found some interesting ways we could take the technology based on our analysis of the human voice. For instance, there’s a control called Bats that extracts everything but the breathy, buzzy information: It’s an instant gravelly superhero sound.
— David Weiss
Please note: When you buy products through links on this page, we may earn an affiliate commission.